Machine Learning Pipeline Design Overview:
In our project, we implement a comprehensive Machine Learning (ML) pipeline using Amazon Web Services (AWS) for the creation, training, deployment, and re-training of models
Pipeline flow
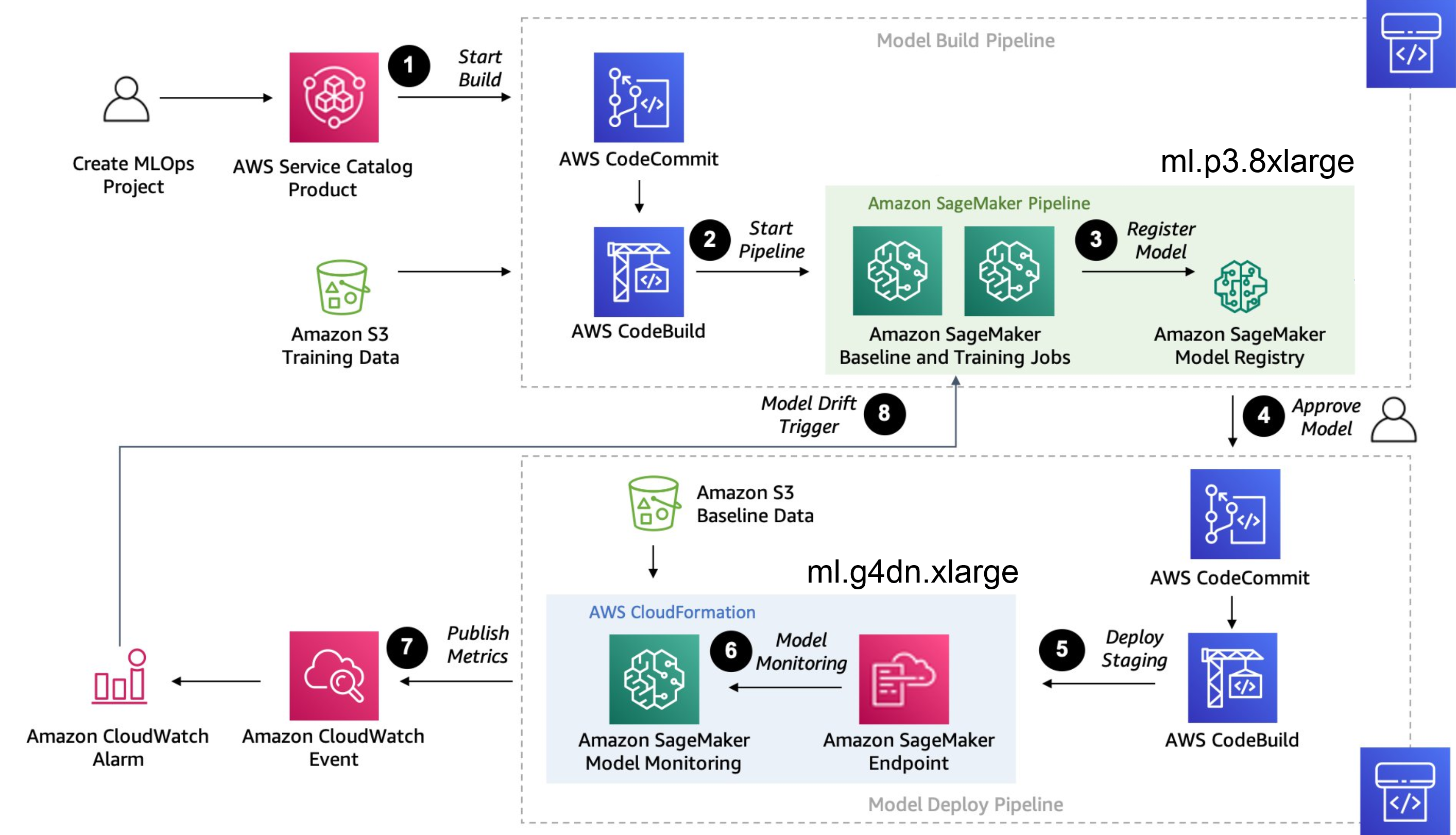
Training Process
Build model
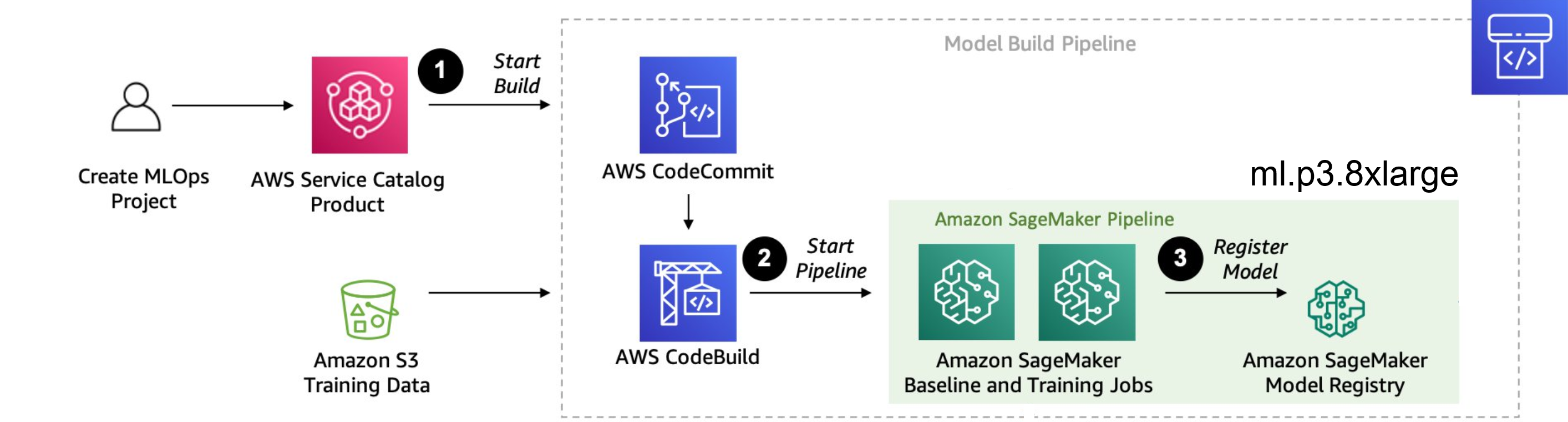
- Creat Project and build sturcture for model in AWS then Commit Code to AWS Load Training Data set in Amazon s3 with codeBuild to Start Pipeline.
- Training Model in SageMaker Pipeline:
-
The training process begins with the initiation of the SageMaker pipeline, which orchestrates the training of models. This pipeline operates on an ml.p3.8xlarge instance, equipped with 4 NVIDIA V100 GPUs, each with 16 GB of RAM, totaling 64 GB VRAM. This powerful configuration enables efficient model training. The estimated duration for model training is approximately 24 hours.
-
Within the SageMaker environment, we manage two models simultaneously: the existing (old) model and the new ground truth model. This setup allows for the comparison and evaluation of the performance between the two models, facilitating iterative improvements in our machine learning algorithms.
- we will get Registry of Amazon SageMaker Model that are trained,includes details such as model versions, training configurations, evaluation metrics, and other relevant information.
Deploy Process
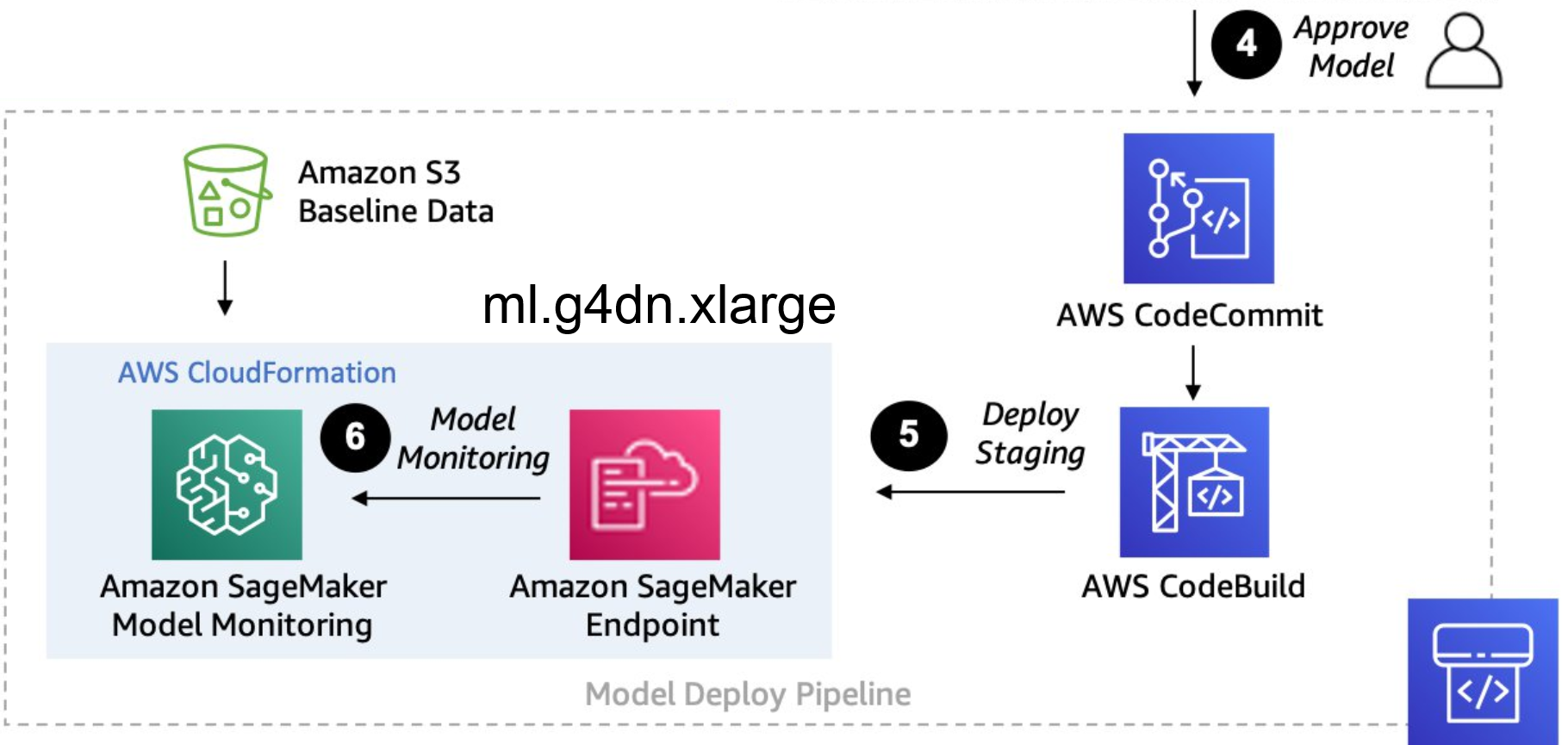
- Model Selection and Approval:
- Once a model demonstrates high or acceptable accuracy during evaluation, we proceed to select it for deployment. This selection process involves careful consideration of the model's performance metrics. Upon approval, we commit the chosen model and initiate the deployment process. This involves building the necessary artifacts for deployment, ensuring that the model is ready to be deployed into production.
- Deployment to Amazon SageMaker Inference Endpoint:
- After selecting a model with satisfactory accuracy, we proceed with its deployment to an Amazon SageMaker inference endpoint. This endpoint is powered by an ml.g4dn.xlarge instance equipped with a single NVIDIA V100 GPU boasting 16 GB GPU RAM. It operates continuously, running 24/7 to serve the inference endpoint, ensuring uninterrupted availability for processing inference requests.
- SageMaker endpoint model will be monitored to measure prediction accuracy every weeks or days according to our setting.
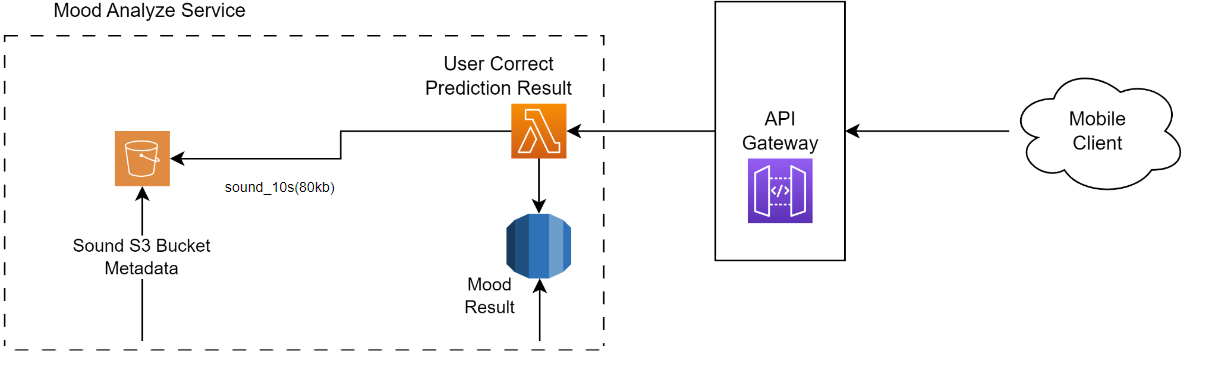
- if model model made incorrect predictions , Users can edit and correct incorrect predictions, saving the corrected data to an S3 bucket. This corrected data serves as baseline ground truth and contributes to a new dataset for training future models.
Retrain Process
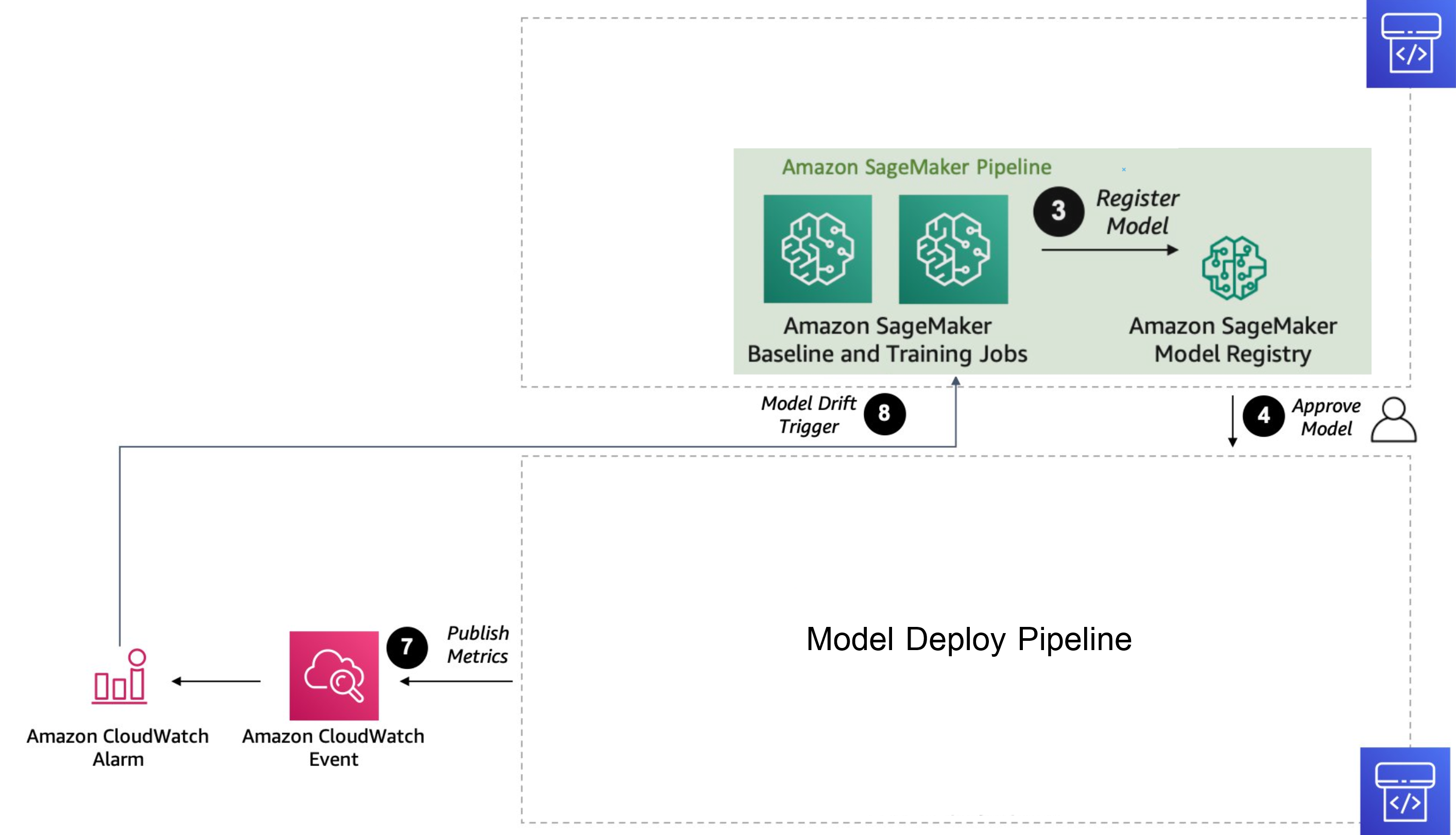
- If accuracy of model lower then our threshold , Amazon CloudWatch Event will alert and Trigger Pipeline Build model.
- Trigger Sagemaker Pipeline that run in ml.p3.8xlarge will use the new ground truth that user has updated to re-training old model and new model.